Subspace Interventions#
__author__ = "Zhengxuan Wu"
__version__ = "11/28/2023"
Overview#
Subspace of the basis may be used to represent different orthogonal causal variables. In other words, each column or each partition of columns may be used to represent different high-level causal model. In this tutorial, we want to illustrate how to setup the intervenable to do this.
We introduce a new concept of subspace intervention. For the intervention, you can specify if you only want to intervene on a subspace rather than the fullspace.
Then, you can intervene on different subspaces given your examples in a batch, and test for different counterfactual behaviors. Accordingly, you can also train different subspaces to target different counterfactual behaviors using DAS.
Set-up#
try:
# This library is our indicator that the required installs
# need to be done.
import pyvene
except ModuleNotFoundError:
!pip install git+https://github.com/stanfordnlp/pyvene.git
import pandas as pd
from pyvene import embed_to_distrib, top_vals, format_token
from pyvene import (
IntervenableModel,
RotatedSpaceIntervention,
RepresentationConfig,
IntervenableConfig,
)
from pyvene import create_gpt2
%config InlineBackend.figure_formats = ['svg']
from plotnine import (
ggplot,
geom_tile,
aes,
facet_wrap,
theme,
element_text,
geom_bar,
geom_hline,
scale_y_log10,
)
config, tokenizer, gpt = create_gpt2()
loaded model
Subspace alignment config#
You just need to specify your intial subspace partition in the config.
Currently, only DAS-related interventions are supporting this. But the concept of subspace intervention can be extended to other types of interventions as well (e.g., vanilla intervention where swapping a subset of activations).
def simple_subspace_position_config(
model_type, intervention_type, layer, subspace_partition=[[0, 384], [384, 768]]
):
config = IntervenableConfig(
model_type=model_type,
representations=[
RepresentationConfig(
layer, # layer
intervention_type, # repr intervention type
"pos", # intervention unit
1, # max number of unit
subspace_partition=subspace_partition,
)
],
intervention_types=RotatedSpaceIntervention,
)
return config
base = tokenizer("The capital of Spain is", return_tensors="pt")
sources = [tokenizer("The capital of Italy is", return_tensors="pt")]
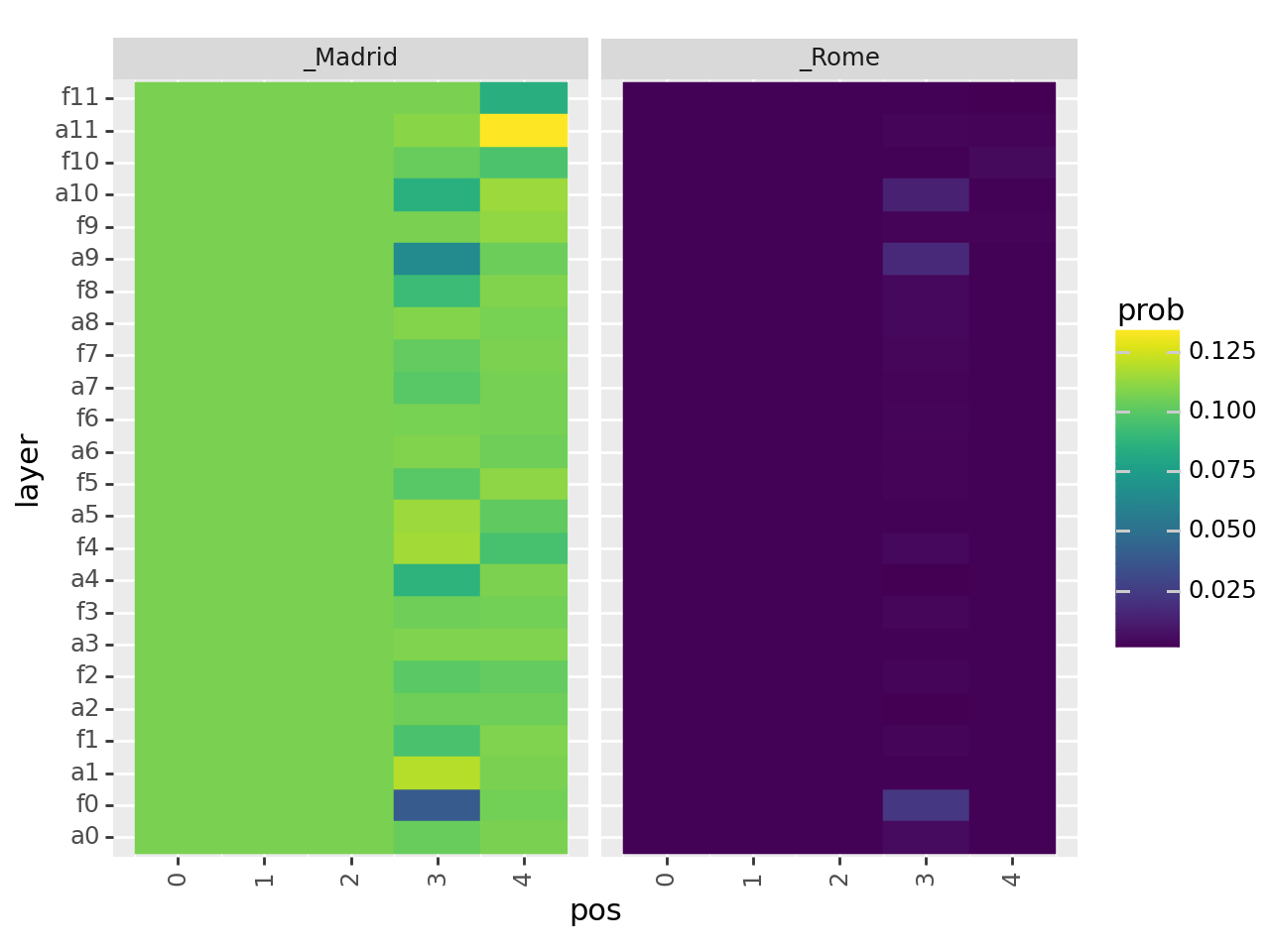
Patch Patching on the First Subspace of Position-aligned Tokens#
We path patch on the subspace (indexing from 0 to 384) of two modules on each layer:
[1] MLP output (the MLP output will be from another example)
[2] MHA input (the self-attention module input will be from another module)
# should finish within 1 min with a standard 12G GPU
tokens = tokenizer.encode(" Madrid Rome")
data = []
for layer_i in range(gpt.config.n_layer):
config = simple_subspace_position_config(
type(gpt), "mlp_output", layer_i
)
intervenable = IntervenableModel(config, gpt)
for k, v in intervenable.interventions.items():
v.set_interchange_dim(768)
for pos_i in range(len(base.input_ids[0])):
_, counterfactual_outputs = intervenable(
base,
sources,
{"sources->base": ([[[pos_i]]], [[[pos_i]]])},
subspaces=[[[0]]],
)
distrib = embed_to_distrib(
gpt, counterfactual_outputs.last_hidden_state, logits=False
)
for token in tokens:
data.append(
{
"token": format_token(tokenizer, token),
"prob": float(distrib[0][-1][token]),
"layer": f"f{layer_i}",
"pos": pos_i,
"type": "mlp_output",
}
)
config = simple_subspace_position_config(
type(gpt), "attention_input", layer_i
)
intervenable = IntervenableModel(config, gpt)
for k, v in intervenable.interventions.items():
v.set_interchange_dim(768)
for pos_i in range(len(base.input_ids[0])):
_, counterfactual_outputs = intervenable(
base,
sources,
{"sources->base": ([[[pos_i]]], [[[pos_i]]])},
subspaces=[[[0]]],
)
distrib = embed_to_distrib(
gpt, counterfactual_outputs.last_hidden_state, logits=False
)
for token in tokens:
data.append(
{
"token": format_token(tokenizer, token),
"prob": float(distrib[0][-1][token]),
"layer": f"a{layer_i}",
"pos": pos_i,
"type": "attention_input",
}
)
df = pd.DataFrame(data)
df["layer"] = df["layer"].astype("category")
df["token"] = df["token"].astype("category")
nodes = []
for l in range(gpt.config.n_layer - 1, -1, -1):
nodes.append(f"f{l}")
nodes.append(f"a{l}")
df["layer"] = pd.Categorical(df["layer"], categories=nodes[::-1], ordered=True)
g = (
ggplot(df)
+ geom_tile(aes(x="pos", y="layer", fill="prob", color="prob"))
+ facet_wrap("~token")
+ theme(axis_text_x=element_text(rotation=90))
)
print(g)