Introduction to pyvene#
This tutorial shows simple runnable code snippets of how to do different kinds of interventions on neural networks with pyvene.
![]()
__author__ = "Zhengxuan Wu"
__version__ = "02/01/2024"
Table of Contents#
Set-up#
try:
# This library is our indicator that the required installs
# need to be done.
import pyvene
except ModuleNotFoundError:
!pip install git+https://github.com/stanfordnlp/pyvene.git
pyvene 101#
Before we get started, here are a couple of core notations that are used in this library:
Base example: this is the example we are intervening on, or, we are intervening on the computation graph of the model running the Base example.
Source example or representations: this is the source of our intervention. We use Source to intervene on Base.
component: this is the
nn.modulewe are intervening in a pytorch-based NN. For models supported by this library, you can use directly access via str, or use the abstract names defined in the config file (e.g.,h[0].mlp.outputormlp_outputwith other fields).unit: this is the axis of our intervention. If we say our unit is
pos(position), then you are intervening on each token position.unit_locations: this list gives you the percisely location of your intervention. It is the locations of the unit of analysis you are specifying. For instance, if your
unitispos, and yourunit_locationis 3, then it means you are intervening on the third token. If this field is left asNone, then no selection will be taken, i.e., you can think of you are getting the raw tensor and you can do whatever you want.intervention_type or intervention: this field specifies the intervention you can perform. It can be a primitive type, or it can be a function or a lambda expression for simple interventions. One benefit of using primitives is speed and systematic training schemes. You can also save and load interventions if you use the supported primitives.
Get Attention Weights#
import pyvene as pv
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "gpt2"
# Do not use SDPA attention because we cannot hook to attn_dropout
gpt2 = AutoModelForCausalLM.from_pretrained(model_name, attn_implementation="eager")
tokenizer = AutoTokenizer.from_pretrained(model_name)
pv_gpt2 = pv.IntervenableModel({
"layer": 10,
"component": "attention_weight",
"intervention_type": pv.CollectIntervention}, model=gpt2)
base = "When John and Mary went to the shops, Mary gave the bag to"
collected_attn_w = pv_gpt2(
base = tokenizer(base, return_tensors="pt"
), unit_locations={"base": [h for h in range(12)]}
)[0][-1][0]
/u/nlp/anaconda/main/anaconda3/envs/wuzhengx-310/lib/python3.10/site-packages/transformers/utils/hub.py:124: FutureWarning: Using `TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
warnings.warn(
Get Attention Weights with Direct Access String#
import torch
import pyvene as pv
# gpt2 helper loading model from HuggingFace
_, tokenizer, gpt2 = pv.create_gpt2()
pv_gpt2 = pv.IntervenableModel({
# based on the module printed above, you can access via string, input means the input to the module
"component": "h[10].attn.attn_dropout.input",
# you can also initialize the intervention outside
"intervention": pv.CollectIntervention()}, model=gpt2)
base = "When John and Mary went to the shops, Mary gave the bag to"
collected_attn_w = pv_gpt2(
base = tokenizer(base, return_tensors="pt"
), unit_locations={"base": [h for h in range(12)]}
)[0][-1][0]
loaded model
Get Attention Weights with a Function#
import torch
import copy
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
cached_w = {}
def pv_patcher(b, s): cached_w["attn_w"] = copy.deepcopy(b.data)
pv_gpt2 = pv.IntervenableModel({
"component": "h[10].attn.attn_dropout.input",
"intervention": pv_patcher}, model=gpt2)
base = "When John and Mary went to the shops, Mary gave the bag to"
_ = pv_gpt2(tokenizer(base, return_tensors="pt"))
torch.allclose(collected_attn_w, cached_w["attn_w"].unsqueeze(dim=0))
loaded model
Set Activation to Zeros#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
# define the component to zero-out
pv_gpt2 = pv.IntervenableModel({
"layer": 0, "component": "mlp_output",
"source_representation": torch.zeros(gpt2.config.n_embd)
}, model=gpt2)
# run the intervened forward pass
intervened_outputs = pv_gpt2(
base = tokenizer("The capital of Spain is", return_tensors="pt"),
# we define the intervening token dynamically
unit_locations={"base": 3},
output_original_output=True # False then the first element in the tuple is None
)
loaded model
Set Activation to Zeros with a Lambda Expression#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
# indices are specified in the intervention
mask = torch.ones(1, 5, 768)
mask[:,3,:] = 0.
# define the component to zero-out
pv_gpt2 = pv.IntervenableModel({
"component": "h[0].mlp.output", "intervention": lambda b, s: b*mask
}, model=gpt2)
# run the intervened forward pass
intervened_outputs_fn = pv_gpt2(
base = tokenizer("The capital of Spain is", return_tensors="pt")
)
torch.allclose(
intervened_outputs[1].last_hidden_state,
intervened_outputs_fn[1].last_hidden_state
)
loaded model
True
Set Activation to Zeros with a Lambda Expression and Subspace notation#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
# indices are specified in the intervention
def pv_patcher(b, s, sp):
mask = torch.ones(1, 5, 768)
mask[:,sp[0][0],:] = 0.
return b*mask
# define the component to zero-out
pv_gpt2 = pv.IntervenableModel({
"component": "h[0].mlp.output", "intervention": pv_patcher
}, model=gpt2)
# run the intervened forward pass
intervened_outputs_fn = pv_gpt2(
base = tokenizer("The capital of Spain is", return_tensors="pt"),
subspaces=3,
)
torch.allclose(
intervened_outputs[1].last_hidden_state,
intervened_outputs_fn[1].last_hidden_state
)
loaded model
True
Set Activations to Zeros with Subspaces#
The notion of subspace means the actual dimensions you are intervening. If we have a representation in a size of 512, the first 128 activation values are its subspace activations.
import torch
import pyvene as pv
# built-in helper to get a HuggingFace model
_, tokenizer, gpt2 = pv.create_gpt2()
# create with dict-based config
pv_config = pv.IntervenableConfig({
"layer": 0, "component": "mlp_output"})
#initialize model
pv_gpt2 = pv.IntervenableModel(pv_config, model=gpt2)
# run an intervened forward pass
intervened_outputs = pv_gpt2(
# the intervening base input
base=tokenizer("The capital of Spain is", return_tensors="pt"),
# the location to intervene at (3rd token)
unit_locations={"base": 3},
# the individual dimensions targetted
subspaces=[10,11,12],
source_representations=torch.zeros(gpt2.config.n_embd)
)
# sharing
pv_gpt2.save("./tmp/")
loaded model
Directory './tmp/' already exists.
Interchange Interventions#
Instead of a static vector, we can intervene the model with activations sampled from a different forward run. We call this interchange intervention, where intervention happens between two examples and we are interchanging activations between them.
import torch
import pyvene as pv
# built-in helper to get a HuggingFace model
_, tokenizer, gpt2 = pv.create_gpt2()
# create with dict-based config
pv_config = pv.IntervenableConfig({
"layer": 0,
"component": "mlp_output"},
intervention_types=pv.VanillaIntervention
)
#initialize model
pv_gpt2 = pv.IntervenableModel(
pv_config, model=gpt2)
# run an interchange intervention
intervened_outputs = pv_gpt2(
# the base input
base=tokenizer(
"The capital of Spain is",
return_tensors = "pt"),
# the source input
sources=tokenizer(
"The capital of Italy is",
return_tensors = "pt"),
# the location to intervene at (3rd token)
unit_locations={"sources->base": 3},
# the individual dimensions targeted
subspaces=[10,11,12]
)
loaded model
Intervention Configuration#
You can also initialize the config without the lazy dictionary passing by enabling more options, e.g., the mode of these interventions are executed.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
# standalone configuration object
config = pv.IntervenableConfig([
{
"layer": _,
"component": "mlp_output",
"source_representation": torch.zeros(
gpt2.config.n_embd)
} for _ in range(4)],
mode="parallel"
)
# this object is serializable
print(config)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
intervened_outputs = pv_gpt2(
base = tokenizer("The capital of Spain is", return_tensors="pt"),
unit_locations={"base": 3}
)
loaded model
IntervenableConfig
{
"model_type": "None",
"representations": [
{
"layer": 0,
"component": "mlp_output",
"unit": "pos",
"max_number_of_units": 1,
"low_rank_dimension": null,
"intervention_type": null,
"intervention": null,
"subspace_partition": null,
"group_key": null,
"intervention_link_key": null,
"moe_key": null,
"source_representation": "PLACEHOLDER",
"hidden_source_representation": null
},
{
"layer": 1,
"component": "mlp_output",
"unit": "pos",
"max_number_of_units": 1,
"low_rank_dimension": null,
"intervention_type": null,
"intervention": null,
"subspace_partition": null,
"group_key": null,
"intervention_link_key": null,
"moe_key": null,
"source_representation": "PLACEHOLDER",
"hidden_source_representation": null
},
{
"layer": 2,
"component": "mlp_output",
"unit": "pos",
"max_number_of_units": 1,
"low_rank_dimension": null,
"intervention_type": null,
"intervention": null,
"subspace_partition": null,
"group_key": null,
"intervention_link_key": null,
"moe_key": null,
"source_representation": "PLACEHOLDER",
"hidden_source_representation": null
},
{
"layer": 3,
"component": "mlp_output",
"unit": "pos",
"max_number_of_units": 1,
"low_rank_dimension": null,
"intervention_type": null,
"intervention": null,
"subspace_partition": null,
"group_key": null,
"intervention_link_key": null,
"moe_key": null,
"source_representation": "PLACEHOLDER",
"hidden_source_representation": null
}
],
"intervention_types": "<class 'pyvene.models.interventions.VanillaIntervention'>",
"mode": "parallel",
"sorted_keys": "None",
"intervention_dimensions": "None"
}
Addition Intervention#
Activation swap is one kind of interventions we can perform. Here is another simple one: pv.AdditionIntervention, which adds the sampled representation into the Base run.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig({
"layer": 0,
"component": "mlp_input"},
pv.AdditionIntervention
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
intervened_outputs = pv_gpt2(
base = tokenizer(
"The Space Needle is in downtown",
return_tensors="pt"
),
unit_locations={"base": [[[0, 1, 2, 3]]]},
source_representations = torch.rand(gpt2.config.n_embd)
)
loaded model
Trainable Intervention#
Interventions can contain trainable parameters, and hook-up with the model to receive gradients end-to-end. They are often useful in searching for an particular interpretation of the representation.
The following example does a single step gradient calculation to push the model to generate Rome after the intervention. If we can train such intervention at scale with low loss, it means you have a causal grab onto your model. In terms of interpretability, that means, somehow you find a representation (not the original one since its trained) that maps onto the capital output.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
das_config = pv.IntervenableConfig({
"layer": 8,
"component": "block_output",
"low_rank_dimension": 1},
# this is a trainable low-rank rotation
pv.LowRankRotatedSpaceIntervention
)
das_gpt2 = pv.IntervenableModel(das_config, model=gpt2)
last_hidden_state = das_gpt2(
base = tokenizer(
"The capital of Spain is",
return_tensors="pt"
),
sources = tokenizer(
"The capital of Italy is",
return_tensors="pt"
),
unit_locations={"sources->base": 3}
)[-1].last_hidden_state[:,-1]
# golden counterfacutual label as Rome
label = tokenizer.encode(
" Rome", return_tensors="pt")
logits = torch.matmul(
last_hidden_state, gpt2.wte.weight.t())
m = torch.nn.CrossEntropyLoss()
loss = m(logits, label.view(-1))
loss.backward()
loaded model
Activation Collection with Intervention#
You can also collect activations with our provided pv.CollectIntervention intervention. More importantly, this can be used interchangably with other interventions. You can collect something from an intervened model.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig({
"layer": 10,
"component": "block_output",
"intervention_type": pv.CollectIntervention}
)
pv_gpt2 = pv.IntervenableModel(
config, model=gpt2)
collected_activations = pv_gpt2(
base = tokenizer(
"The capital of Spain is",
return_tensors="pt"
), unit_locations={"sources->base": 3}
)[0][-1]
loaded model
Activation Collection at Downstream of a Intervened Model#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig({
"layer": 8,
"component": "block_output",
"intervention_type": pv.VanillaIntervention}
)
config.add_intervention({
"layer": 10,
"component": "block_output",
"intervention_type": pv.CollectIntervention})
pv_gpt2 = pv.IntervenableModel(
config, model=gpt2)
collected_activations = pv_gpt2(
base = tokenizer(
"The capital of Spain is",
return_tensors="pt"
),
sources = [tokenizer(
"The capital of Italy is",
return_tensors="pt"
), None], unit_locations={"sources->base": 3}
)[0][-1]
loaded model
Intervene on a Single Neuron#
We want to provide a good user interface so that interventions can be done easily by people with less pytorch or programming experience. Meanwhile, we also want to be flexible and provide the depth of control required for highly specific tasks. Here is an example where we intervene on a specific neuron at a specific head of a layer in a model.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig({
"layer": 8,
"component": "head_attention_value_output",
"unit": "h.pos",
"intervention_type": pv.CollectIntervention}
)
pv_gpt2 = pv.IntervenableModel(
config, model=gpt2)
collected_activations = pv_gpt2(
base = tokenizer(
"The capital of Spain is",
return_tensors="pt"
),
unit_locations={
# GET_LOC is a helper.
# (3,3) means head 3 position 3
"base": pv.GET_LOC((3,3))
},
# the notion of subspace is used to target neuron 0.
subspaces=[0]
)[0][-1]
loaded model
Add New Intervention Type#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
class MultiplierIntervention(
pv.ConstantSourceIntervention):
def __init__(self, **kwargs):
super().__init__()
def forward(
self, base, source=None, subspaces=None, **kwargs):
return base * 99.0
# run with new intervention type
pv_gpt2 = pv.IntervenableModel({
"intervention_type": MultiplierIntervention},
model=gpt2)
intervened_outputs = pv_gpt2(
base = tokenizer("The capital of Spain is",
return_tensors="pt"),
unit_locations={"base": 3})
loaded model
Recurrent NNs (Intervene a Specific Timestep)#
Existing intervention libraries focus on Transformer models. They often lack of supports for GRUs, LSTMs or any state-space model. The fundemental problem is in the hook mechanism provided by PyTorch. Hook is attached to a module before runtime. Models like GRUs will lead to undesired callback from the hook as there is no notion of state or time of the hook.
We make our hook stateful, so you can intervene on recurrent NNs like GRUs. This notion of time will become useful when intervening on Transformers yet want to unroll the causal effect during generation as well.
import torch
import pyvene as pv
_, _, gru = pv.create_gru_classifier(
pv.GRUConfig(h_dim=32))
pv_gru = pv.IntervenableModel({
"component": "cell_output",
"unit": "t",
"intervention_type": pv.ZeroIntervention},
model=gru)
rand_t = torch.rand(1,10, gru.config.h_dim)
intervened_outputs = pv_gru(
base = {"inputs_embeds": rand_t},
unit_locations={"base": 3})
loaded model
Recurrent NNs (Intervene cross Time)#
import torch
import pyvene as pv
# built-in helper to get a GRU
_, _, gru = pv.create_gru_classifier(
pv.GRUConfig(h_dim=32))
# wrap it with config
pv_gru = pv.IntervenableModel({
"component": "cell_output",
# intervening on time
"unit": "t",
"intervention_type": pv.ZeroIntervention},
model=gru)
# run an intervened forward pass
rand_b = torch.rand(1,10, gru.config.h_dim)
rand_s = torch.rand(1,10, gru.config.h_dim)
intervened_outputs = pv_gru(
base = {"inputs_embeds": rand_b},
sources = [{"inputs_embeds": rand_s}],
# intervening time step
unit_locations={"sources->base": (6, 3)})
loaded model
LMs Generation#
You can also intervene the generation call of LMs. Here is a simple example where we try to add a vector into the MLP output when the model decodes.
import torch
import pyvene as pv
# built-in helper to get tinystore
_, tokenizer, tinystory = pv.create_gpt_neo()
emb_happy = tinystory.transformer.wte(
torch.tensor(14628))
pv_tinystory = pv.IntervenableModel([{
"layer": l,
"component": "mlp_output",
"intervention_type": pv.AdditionIntervention
} for l in range(tinystory.config.num_layers)],
model=tinystory
)
# prompt and generate
prompt = tokenizer(
"Once upon a time there was", return_tensors="pt")
unintervened_story, intervened_story = pv_tinystory.generate(
prompt, source_representations=emb_happy*0.3, max_length=256
)
print(tokenizer.decode(
intervened_story[0],
skip_special_tokens=True
))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
loaded model
Once upon a time there was a little girl named Lucy. She was three years old and loved to explore. One day, Lucy was walking in the park when she saw a big, red balloon. She was so excited and wanted to play with it.
But then, a big, mean man came and said, "That balloon is mine! You can't have it!" Lucy was very sad and started to cry.
The man said, "I'm sorry, but I need the balloon for my work. You can have it if you want."
Lucy was so happy and said, "Yes please!" She took the balloon and ran away.
But then, the man said, "Wait! I have an idea. Let's make a deal. If you can guess what I'm going to give you, then you can have the balloon."
Lucy thought for a moment and then said, "I guess I'll have to get the balloon."
The man smiled and said, "That's a good guess! Here you go."
Lucy was so happy and thanked the man. She hugged the balloon and ran off to show her mom.
The end.
intervene on generation with source example passed in. The result will be slightly different since we no longer have a static vector to be added in; it is layerwise addition.
import torch
import pyvene as pv
# built-in helper to get tinystore
_, tokenizer, tinystory = pv.create_gpt_neo()
def pv_patcher(b, s): return b + s*0.1
pv_tinystory = pv.IntervenableModel([{
"layer": l,
"component": "mlp_output",
"intervention": pv_patcher
} for l in range(tinystory.config.num_layers)],
model=tinystory
)
# prompt and generate
prompt = tokenizer(
"Once upon a time there was", return_tensors="pt")
happy_prompt = tokenizer(
" Happy", return_tensors="pt")
_, intervened_story = pv_tinystory.generate(
prompt, happy_prompt,
unit_locations = {"sources->base": 0},
max_length=256
)
print(tokenizer.decode(
intervened_story[0],
skip_special_tokens=True
))
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
loaded model
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Once upon a time there was a little girl named Lucy. She was very excited because she was going to the park. She wanted to go to the park and play.
When she got to the park, she saw a big slide. She was so excited! She ran to the slide and started to climb up. She was so happy.
But then she saw something else. It was a big, scary dog. It was a big, mean dog. He was barking and growling at her. Lucy was scared. She didn't know what to do.
Suddenly, she heard a voice. It was her mommy. She said, "Don't worry, Lucy. I will help you. I will protect you."
Lucy was so happy. She hugged her mommy and they went to the park. They played together and had lots of fun. Lucy was so happy. She was no longer scared.
Advanced Intervention on LMs Generation (Model Steering)#
We also support model steering with interventions during model generation. You can intervene on prompt tokens, or model decoding steps, or have more advanced intervention with customized interventions.
Note that you must set keep_last_dim = True to get token-level representations!
import pyvene as pv
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it")
print("Extracting happy vector ...")
happy_id = tokenizer("happy")['input_ids'][-1]
happy_vector = model.model.embed_tokens.weight[happy_id].to("cuda")
# Create a "happy" addition intervention
class HappyIntervention(pv.ConstantSourceIntervention):
def __init__(self, **kwargs):
super().__init__(
**kwargs,
keep_last_dim=True) # you must set keep_last_dim=True to get tokenized reprs.
self.called_counter = 0
def forward(self, base, source=None, subspaces=None, **kwargs):
if subspaces["logging"]:
print(f"(called {self.called_counter} times) incoming reprs shape:", base.shape)
self.called_counter += 1
return base + subspaces["mag"] * happy_vector
# Mount the intervention to our steering model
pv_config = pv.IntervenableConfig(representations=[{
"layer": 20,
"component": f"model.layers[20].output",
"low_rank_dimension": 1,
"intervention": HappyIntervention(
embed_dim=model.config.hidden_size,
low_rank_dimension=1)}])
pv_model = pv.IntervenableModel(pv_config, model)
pv_model.set_device("cuda")
Extracting happy vector ...
prompt = "Write a story for me about dragon."
prompt = tokenizer.decode(tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=True, add_generation_prompt=True)[1:])
inputs = tokenizer(
prompt, return_tensors="pt", padding=True, truncation=True
).to("cuda")
_, generations = pv_model.generate(
inputs,
unit_locations=None, # set to None means intervention will be applied for each forward call
intervene_on_prompt=True, # intervention will be called for the prompt kv cache call
subspaces=[{"mag": 2.0, "logging": True}], # other metadata
max_new_tokens=10, do_sample=True, temperature=1.0)
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
(called 0 times) incoming reprs shape: torch.Size([1, 17, 2304])
(called 1 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 2 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 3 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 4 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 5 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 6 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 7 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 8 times) incoming reprs shape: torch.Size([1, 1, 2304])
(called 9 times) incoming reprs shape: torch.Size([1, 1, 2304])
Here you go! You can see that the intervention is called 10 times. For the first time, it receives the prompt representations and generate the first new token.
Now, let’s generate some steering results.
_, generations = pv_model.generate(
inputs,
unit_locations=None, # set to None means intervention will be applied for each forward call
intervene_on_prompt=True, # intervention will be called for the prompt kv cache call
subspaces=[{"mag": 70.0, "logging": False}], # other metadata
max_new_tokens=128, do_sample=True, temperature=1.0)
tokenizer.decode(generations[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
"Anya's grandmother, Elara, had always said happy souls were the happiest kind – even happy dragons. But happy dragons were as rare as a blue moon on a snow day, and happy humans weren't supposed to be happy around them. Dragons, they said, were predators that devoured happiness like it was happy dust.\n\nAnya knew better. Happy was a whisper, a happy breeze on the sun-dappled meadow. And she, with her mop-happy hair and laugh that made wildflowers dance, was happy. So she snuck off to the Forbidden Forest, a place where only brave hearts dared to roam"
Great! This is your super-happy model. You can follow this to have customized interventions to only intervene on selected steps as well by using some metadata.
Debiasing with Backpack LMs#
Models like Backpack LMs are built with highly interpretable model components. In its original paper, one motivating experiment is using the sense vectors to debias. Here, we try to reproduce one of the experiments in Fig. 3 (pg. 8).
import torch
import pandas as pd
from plotnine import ggplot, aes, geom_bar, theme, element_text, labs
import pyvene as pv
_, tokenizer, backpack_gpt2 = pv.create_backpack_gpt2()
class MultiplierIntervention(pv.ConstantSourceIntervention):
"""Multiplier intervention"""
def __init__(self, multiplier, **kwargs):
super().__init__(**kwargs)
self.register_buffer('multiplier', torch.tensor(multiplier))
def forward(self, base, source=None, subspaces=None, **kwargs):
return base * self.multiplier
def __str__(self):
return f"MultiplierIntervention()"
for c in [0, 0.7, 1]:
pv_backpack_gpt2 = pv.IntervenableModel({
"component": "backpack.sense_network.output",
"intervention": MultiplierIntervention(c), "unit": "sense.pos"},
model=backpack_gpt2
)
base = tokenizer("When the nurse walked into the room,",
return_tensors="pt", return_attention_mask=False)
intervened_outputs = pv_backpack_gpt2(
base,
unit_locations={
# use pv.GET_LOC((nv, s))
"base": pv.GET_LOC((10,2))
}
)
# plotting
probs = torch.nn.functional.softmax(
intervened_outputs[1].logits[0][-1], dim=0)
data = pv.top_vals(
tokenizer, probs, n=9,
return_results=True
)
df = pd.DataFrame(data, columns=['Word', 'Probability'])
df['Word'] = pd.Categorical(df['Word'], categories=[x[0] for x in data], ordered=True)
plot = (ggplot(df, aes(x='Word', y='Probability'))
+ geom_bar(stat='identity')
+ theme(axis_text_x=element_text(rotation=90, hjust=1),
figure_size=(4, 2))
+ labs(title=f"mul({c})")
)
print(plot)
The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is ignored.
loaded model
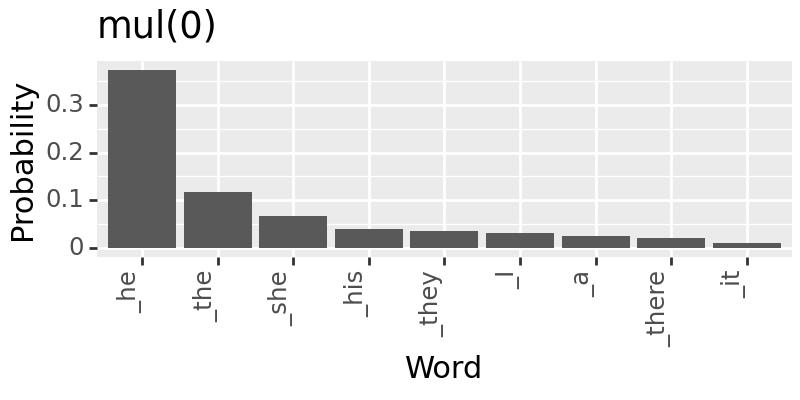
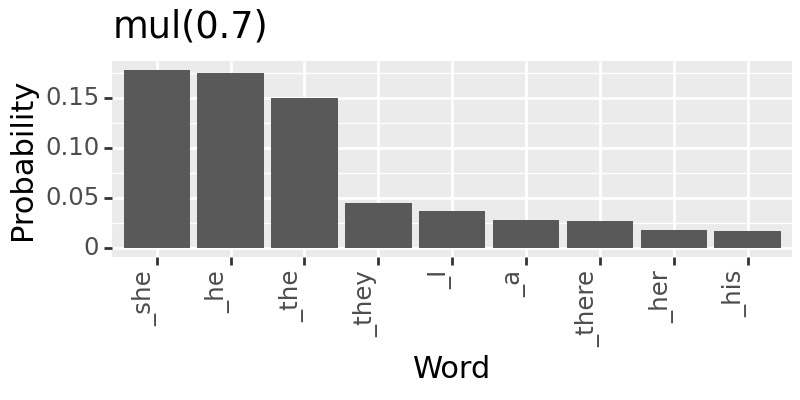
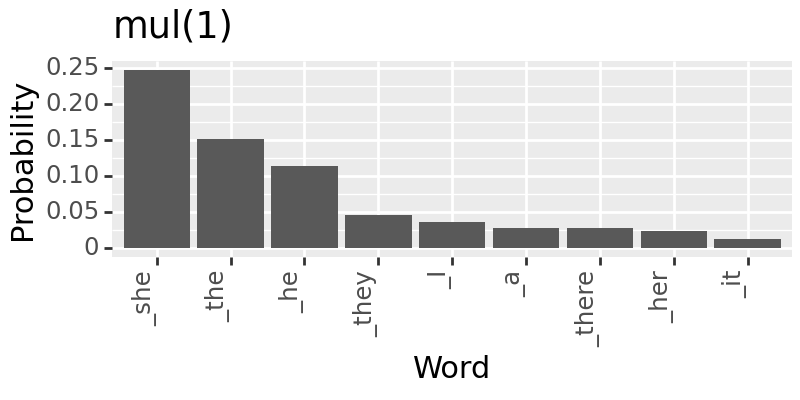
Saving and Loading#
This is one of the benefits of program abstraction. We abstract out the intervention and its schema, so we have a user friendly interface. Furthermore, it allows us to have a serializable configuration file that tells everything about your configuration.
You can then save, share and load interventions easily. Note that you still need your access to the data, if you need to sample Source representations from other examples. But we think this is doable via a separate HuggingFace datasets upload. In the future, there could be an option of coupling this configuration with a specific remote dataset as well.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
# run with new intervention type
pv_gpt2 = pv.IntervenableModel({
"intervention_type": pv.ZeroIntervention},
model=gpt2)
pv_gpt2.save("./tmp/")
loaded model
Directory './tmp/' already exists.
pv_gpt2 = pv.IntervenableModel.load(
"./tmp/",
model=gpt2)
WARNING:root:The key is provided in the config. Assuming this is loaded from a pretrained module.
WARNING:root:Loading trainable intervention from intkey_layer.0.repr.block_output.unit.pos.nunit.1#0.bin.
Multi-Source Interchange Intervention (Parallel Mode)#
What is multi-source? In the examples above, interventions are at most across two examples. We support interventions across many examples. You can sample representations from two inputs, and plut them into a single Base.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
parallel_config = pv.IntervenableConfig([
{"layer": 3, "component": "block_output"},
{"layer": 3, "component": "block_output"}],
# intervene on base at the same time
mode="parallel")
parallel_gpt2 = pv.IntervenableModel(
parallel_config, model=gpt2)
base = tokenizer(
"The capital of Spain is",
return_tensors="pt")
sources = [
tokenizer("The language of Spain is",
return_tensors="pt"),
tokenizer("The capital of Italy is",
return_tensors="pt")]
intervened_outputs = parallel_gpt2(
base, sources,
{"sources->base": (
# each list has a dimensionality of
# [num_intervention, batch, num_unit]
[[[1]],[[3]]], [[[1]],[[3]]])}
)
distrib = pv.embed_to_distrib(
gpt2, intervened_outputs[1].last_hidden_state, logits=False)
pv.top_vals(tokenizer, distrib[0][-1], n=10)
loaded model
_the 0.07233363389968872
_a 0.05731499195098877
_not 0.04443885385990143
_Italian 0.033642884343862534
_often 0.024385808035731316
_called 0.022171705961227417
_known 0.017808808013796806
_that 0.016059240326285362
_" 0.012973357923328876
_an 0.012878881767392159
Multi-Source Interchange Intervention (Serial Mode)#
Or you can do them sequentially, where you intervene among your Source examples, and get some intermediate states before merging the activations into the Base run.
config = pv.IntervenableConfig([
{"layer": 3, "component": "block_output"},
{"layer": 10, "component": "block_output"}],
# intervene on base one after another
mode="serial")
pv_gpt2 = pv.IntervenableModel(
config, model=gpt2)
base = tokenizer(
"The capital of Spain is",
return_tensors="pt")
sources = [
tokenizer("The language of Spain is",
return_tensors="pt"),
tokenizer("The capital of Italy is",
return_tensors="pt")]
intervened_outputs = pv_gpt2(
base, sources,
# intervene in serial at two positions
{"source_0->source_1": 1,
"source_1->base" : 4})
distrib = pv.embed_to_distrib(
gpt2, intervened_outputs[1].last_hidden_state, logits=False)
pv.top_vals(tokenizer, distrib[0][-1], n=10)
_the 0.06737838685512543
_a 0.059834375977516174
_not 0.04629501700401306
_Italian 0.03623826056718826
_often 0.021700192242860794
_called 0.01840786263346672
_that 0.0157712884247303
_known 0.014391838572919369
_an 0.013535155914723873
_very 0.013022392988204956
Multi-Source Interchange Intervention with Subspaces (Parallel Mode)#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
{"layer": 0, "component": "block_output",
"subspace_partition":
[[0, 128], [128, 256]]}]*2,
intervention_types=pv.VanillaIntervention,
# act in parallel
mode="parallel"
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
sources = [tokenizer("The capital of Italy is", return_tensors="pt"),
tokenizer("The capital of China is", return_tensors="pt")]
intervened_outputs = pv_gpt2(
base, sources,
# on same position
{"sources->base": 4},
# on different subspaces
subspaces=[[[0]], [[1]]],
)
loaded model
Multi-Source Interchange Intervention with Subspaces (Serial Mode)#
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
{"layer": 0, "component": "block_output",
"subspace_partition": [[0, 128], [128, 256]]},
{"layer": 2, "component": "block_output",
"subspace_partition": [[0, 128], [128, 256]]}],
intervention_types=pv.VanillaIntervention,
# act in parallel
mode="serial"
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
sources = [tokenizer("The capital of Italy is", return_tensors="pt"),
tokenizer("The capital of China is", return_tensors="pt")]
intervened_outputs = pv_gpt2(
base, sources,
# serialized intervention
# order is based on sources list
{"source_0->source_1": 3, "source_1->base": 4},
# on different subspaces
subspaces=[[[0]], [[1]]],
)
loaded model
Interchange Intervention Training (IIT)#
Interchange intervention training (IIT) is a technique of inducing causal structures into neural models. This library naturally supports this. By training IIT, you can simply turn the gradient on for the wrapping model. In this way, your model can be trained with your interventional signals.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
pv_gpt2 = pv.IntervenableModel({
"layer": 8, "component": "block_output"},
model=gpt2
)
pv_gpt2.enable_model_gradients()
print("number of params:", pv_gpt2.count_parameters())
# run counterfactual forward as usual
base = tokenizer("The capital of Spain is", return_tensors="pt")
sources = [
tokenizer("The capital of Italy is", return_tensors="pt"),
]
base_outputs, counterfactual_outputs = pv_gpt2(
base, sources, {"sources->base": ([[[3]]], [[[3]]])}, output_original_output=True
)
print(counterfactual_outputs.last_hidden_state - base_outputs.last_hidden_state)
# call backward will put gradients on model's weights
counterfactual_outputs.last_hidden_state.sum().backward()
loaded model
number of params: 124439808
tensor([[[ 0.0022, -0.1783, -0.2780, ..., 0.0477, -0.2069, 0.1093],
[ 0.0385, 0.0886, -0.6608, ..., 0.0104, -0.4946, 0.6148],
[ 0.2377, -0.2312, 0.0308, ..., 0.1085, 0.0456, 0.2494],
[-0.0034, 0.0088, -0.2219, ..., 0.1198, 0.0759, 0.3953],
[ 0.4635, 0.2698, -0.3185, ..., -0.2946, 0.2634, 0.2714]]],
grad_fn=<SubBackward0>)
pyvene 102#
Now, you are pretty familiar with pyvene basic APIs. There are more to come. We support all sorts of weird interventions, and we encapsulate them as objects so that, even they are super weird (e.g., nested, multiple locations, different types), you can share them easily with others. BTW, if the intervention is trainable, the artifacts will be saved and shared as well.
With that, here are a couple of additional APIs.
Grouping#
You can group interventions together so that they always receive the same input when you want to use them to get activations at different places. Here is an example, where you are taking in the same Source example, you fetch activations twice: once in position 3 and layer 0, once in position 4 and layer 2. You don’t have to pass in another dummy Source.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
{"layer": 0, "component": "block_output", "group_key": 0},
{"layer": 2, "component": "block_output", "group_key": 0}],
intervention_types=pv.VanillaIntervention,
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
sources = [tokenizer("The capital of Italy is", return_tensors="pt")]
intervened_outputs = pv_gpt2(
base, sources,
{"sources->base": ([
[[3]], [[4]] # these two are for two interventions
], [ # source position 3 into base position 4
[[3]], [[4]]
])}
)
loaded model
Intervention Skipping in Runtime#
You may configure a lot of interventions, but during training, not every example will have to use all of them. So, you can skip interventions for different examples differently.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
# these are equivalent interventions
# we create them on purpose
{"layer": 0, "component": "block_output"},
{"layer": 0, "component": "block_output"},
{"layer": 0, "component": "block_output"}],
intervention_types=pv.VanillaIntervention,
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
source = tokenizer("The capital of Italy is", return_tensors="pt")
# skipping 1, 2 and 3
_, pv_out1 = pv_gpt2(base, [None, None, source],
{"sources->base": ([None, None, [[4]]], [None, None, [[4]]])})
_, pv_out2 = pv_gpt2(base, [None, source, None],
{"sources->base": ([None, [[4]], None], [None, [[4]], None])})
_, pv_out3 = pv_gpt2(base, [source, None, None],
{"sources->base": ([[[4]], None, None], [[[4]], None, None])})
# should have the same results
print(
torch.equal(pv_out1.last_hidden_state, pv_out2.last_hidden_state),
torch.equal(pv_out2.last_hidden_state, pv_out3.last_hidden_state)
)
loaded model
True True
Subspace Partition#
You can partition your subspace before hand. If you don’t, the library assumes you each neuron is in its own subspace. In this example, you partition your subspace into two continous chunk, [0, 128), [128,256), which means all the neurons from index 0 upto 127 are along to partition 1. During runtime, you can intervene on all the neurons in the same parition together.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
# they are linked to manipulate the same representation
# but in different subspaces
{"layer": 0, "component": "block_output",
# subspaces can be partitioned into continuous chunks
# [i, j] are the boundary indices
"subspace_partition": [[0, 128], [128, 256]]}],
intervention_types=pv.VanillaIntervention,
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
source = tokenizer("The capital of Italy is", return_tensors="pt")
# using intervention skipping for subspace
intervened_outputs = pv_gpt2(
base, [source],
{"sources->base": 4},
# intervene only only dimensions from 128 to 256
subspaces=1,
)
loaded model
Intervention Linking#
Interventions can be linked to share weights and share subspaces. Here is an example of how to link interventions together. If interventions are trainable, then their weights are tied as well.
Why this is useful? it is because sometimes, you may want to intervene on different subspaces differently. Say you have a representation in a size of 512, and you hypothesize the first half represents A, and the second half represents B, you can then use the subspace intervention to test it out. With trainable interventions, you can also optimize your interventions on the same representation yet with different subspaces.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
# they are linked to manipulate the same representation
# but in different subspaces
{"layer": 0, "component": "block_output",
"subspace_partition": [[0, 128], [128, 256]], "intervention_link_key": 0},
{"layer": 0, "component": "block_output",
"subspace_partition": [[0, 128], [128, 256]], "intervention_link_key": 0}],
intervention_types=pv.VanillaIntervention,
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
source = tokenizer("The capital of Italy is", return_tensors="pt")
# using intervention skipping for subspace
_, pv_out1 = pv_gpt2(
base, [None, source],
# 4 means token position 4
{"sources->base": ([None, [[4]]], [None, [[4]]])},
# 1 means the second partition in the config
subspaces=[None, [[1]]],
)
_, pv_out2 = pv_gpt2(
base,
[source, None],
{"sources->base": ([[[4]], None], [[[4]], None])},
subspaces=[[[1]], None],
)
print(torch.equal(pv_out1.last_hidden_state, pv_out2.last_hidden_state))
# subspaces provide a list of index and they can be in any order
_, pv_out3 = pv_gpt2(
base,
[source, source],
{"sources->base": ([[[4]], [[4]]], [[[4]], [[4]]])},
subspaces=[[[0]], [[1]]],
)
_, pv_out4 = pv_gpt2(
base,
[source, source],
{"sources->base": ([[[4]], [[4]]], [[[4]], [[4]]])},
subspaces=[[[1]], [[0]]],
)
print(torch.equal(pv_out3.last_hidden_state, pv_out4.last_hidden_state))
loaded model
True
True
Other than intervention linking, you can also share interventions at the same component across multiple positions via setting a flag in the intervention object. It will have the same effect as creating one intervention per location and linking them all together.
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
config = pv.IntervenableConfig([
# they are linked to manipulate the same representation
# but in different subspaces
{"layer": 0, "component": "block_output", "intervention_link_key": 0},
{"layer": 0, "component": "block_output", "intervention_link_key": 0}],
intervention_types=pv.VanillaIntervention,
)
pv_gpt2 = pv.IntervenableModel(config, model=gpt2)
base = tokenizer("The capital of Spain is", return_tensors="pt")
source = tokenizer("The capital of Italy is", return_tensors="pt")
_, pv_out = pv_gpt2(
base,
[source, source],
# swap 3rd and 4th token reprs from the same source to the base
{"sources->base": ([[[4]], [[3]]], [[[4]], [[3]]])},
)
keep_last_dim_config = pv.IntervenableConfig([
# they are linked to manipulate the same representation
# but in different subspaces
{"layer": 0, "component": "block_output",
"intervention": pv.VanillaIntervention(keep_last_dim=True)}]
)
keep_last_dim_pv_gpt2 = pv.IntervenableModel(keep_last_dim_config, model=gpt2)
_, keep_last_dim_pv_out = keep_last_dim_pv_gpt2(
base,
[source],
# swap 3rd and 4th token reprs from the same source to the base
{"sources->base": ([[[3,4]]], [[[3,4]]])},
)
keep_last_dim_pv_out.last_hidden_state - pv_out.last_hidden_state
loaded model
tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
Add New Model Type#
import torch
import pyvene as pv
# get a flan-t5 from HuggingFace
from transformers import T5ForConditionalGeneration, T5Tokenizer, T5Config
config = T5Config.from_pretrained("google/flan-t5-small")
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small")
t5 = T5ForConditionalGeneration.from_pretrained(
"google/flan-t5-small", config=config
)
# config the intervention mapping with pv global vars
"""Only define for the block output here for simplicity"""
pv.type_to_module_mapping[type(t5)] = {
"mlp_output": ("encoder.block[%s].layer[1]",
pv.models.constants.CONST_OUTPUT_HOOK),
"attention_input": ("encoder.block[%s].layer[0]",
pv.models.constants.CONST_OUTPUT_HOOK),
}
pv.type_to_dimension_mapping[type(t5)] = {
"mlp_output": ("d_model",),
"attention_input": ("d_model",),
"block_output": ("d_model",),
"head_attention_value_output": ("d_model/num_heads",),
}
# wrap as gpt2
pv_t5 = pv.IntervenableModel({
"layer": 0,
"component": "mlp_output",
"source_representation": torch.zeros(
t5.config.d_model)
}, model=t5)
# then intervene!
base = tokenizer("The capital of Spain is",
return_tensors="pt")
decoder_input_ids = tokenizer(
"", return_tensors="pt").input_ids
base["decoder_input_ids"] = decoder_input_ids
intervened_outputs = pv_t5(
base,
unit_locations={"base": 3}
)
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Composing Complex Intervention Schema: Path Patching#
import pyvene as pv
def path_patching_config(
layer, last_layer,
component="head_attention_value_output", unit="h.pos"
):
intervening_component = [
{"layer": layer, "component": component, "unit": unit, "group_key": 0}]
restoring_components = []
if not component.startswith("mlp_"):
restoring_components += [
{"layer": layer, "component": "mlp_output", "group_key": 1}]
for i in range(layer+1, last_layer):
restoring_components += [
{"layer": i, "component": "attention_output", "group_key": 1},
{"layer": i, "component": "mlp_output", "group_key": 1}
]
intervenable_config = pv.IntervenableConfig(
intervening_component + restoring_components)
return intervenable_config
_, tokenizer, gpt2 = pv.create_gpt2()
pv_gpt2 = pv.IntervenableModel(
path_patching_config(4, gpt2.config.n_layer),
model=gpt2
)
pv_gpt2.save(
save_directory="./tmp/"
)
loaded model
Directory './tmp/' already exists.
pv_gpt2 = pv.IntervenableModel.load(
"./tmp/",
model=gpt2)
WARNING:root:The key is provided in the config. Assuming this is loaded from a pretrained module.
Composing Complex Intervention Schema: Causal Tracing in 15 lines#
import pyvene as pv
def causal_tracing_config(
l, c="mlp_activation", w=10, tl=48):
s = max(0, l - w // 2)
e = min(tl, l - (-w // 2))
config = pv.IntervenableConfig(
[{"component": "block_input"}] +
[{"layer": l, "component": c}
for l in range(s, e)],
[pv.NoiseIntervention] +
[pv.VanillaIntervention]*(e-s))
return config
_, tokenizer, gpt2 = pv.create_gpt2()
pv_gpt2 = pv.IntervenableModel(
causal_tracing_config(4),
model=gpt2
)
loaded model
Inference-time Intervention#
import time, torch
import pyvene as pv
config, tokenizer, llama = pv.create_llama("meta-llama/Llama-2-7b-chat-hf")
# load cached extracted activations from the ITI repo:
# https://github.com/likenneth/honest_llama
o_proj_add_activations = torch.load(
"./tutorials/basic_tutorials/tutorial_data"
"/honest_llama2_chat_7B_o_proj_add_activations.bin"
)
_ = llama.cuda()
pv_llama = pv.IntervenableModel([{
"component": f"model.layers[{i}].self_attn.o_proj.output",
"intervention": pv.AdditionIntervention(
source_representation=o_proj_add_activations[i].to("cuda")
)
} for i in range(config.num_hidden_layers) if torch.count_nonzero(o_proj_add_activations[i])],
model=llama
)
normalizer.cc(51) LOG(INFO) precompiled_charsmap is empty. use identity normalization.
loaded model
q = "What's a cure for insomnia that always works?"
prompt = tokenizer(q, return_tensors="pt").to("cuda")
print("vanilla llama-2-chat:")
st = time.time()
response = llama.generate(**prompt, max_new_tokens=64, do_sample=False)
print(tokenizer.decode(response[0], skip_special_tokens=True))
et = time.time()
elapsed_time = et - st
print('Execution time:', elapsed_time, 'seconds')
print()
print("honest llama-2-chat:")
st = time.time()
_, iti_response = pv_llama.generate(prompt, max_new_tokens=64, do_sample=False)
print(tokenizer.decode(iti_response[0], skip_special_tokens=True))
et = time.time()
elapsed_time = et - st
print('Execution time:', elapsed_time, 'seconds')
vanilla llama-2-chat:
/sailhome/wuzhengx/.local/lib/python3.8/site-packages/transformers/generation/configuration_utils.py:392: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.
warnings.warn(
/sailhome/wuzhengx/.local/lib/python3.8/site-packages/transformers/generation/configuration_utils.py:397: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.
warnings.warn(
What's a cure for insomnia that always works?
Insomnia is a common sleep disorder that can affect anyone, regardless of age or gender. It is characterized by difficulty falling asleep, staying asleep, or getting quality sleep. Insomnia can be caused by a variety of factors, including stress, anxiety, depression, certain
Execution time: 2.1844897270202637 seconds
honest llama-2-chat:
What's a cure for insomnia that always works?
There is no single cure for insomnia that works for everyone, and it's important to address the underlying causes of sleep problems. However, some strategies that may help improve sleep quality and duration include:
1. Practicing relaxation techniques, such as deep breathing, progressive mus
Execution time: 2.6960761547088623 seconds
# save to huggingface directly
try:
pv_llama.save(
"./tmp_llama/",
save_to_hf_hub=True,
hf_repo_name="zhengxuanzenwu/intervenable_honest_llama2_chat_7B"
)
except:
print("You have to login into huggingface hub before running this.")
print("usage: huggingface-cli login")
Directory './tmp_llama/' already exists.
IntervenableModel from HuggingFace Directly#
# others can download from huggingface and use it directly
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import pyvene as pv
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
torch_dtype=torch.bfloat16,
).to("cuda")
pv_model = pv.IntervenableModel.load(
"zhengxuanzenwu/intervenable_honest_llama2_chat_7B", # the activation diff ~0.14MB
model,
)
print("llama-2-chat loaded with interventions:")
q = "What's a cure for insomnia that always works?"
prompt = tokenizer(q, return_tensors="pt").to("cuda")
_, iti_response_shared = pv_model.generate(prompt, max_new_tokens=64, do_sample=False)
print(tokenizer.decode(iti_response_shared[0], skip_special_tokens=True))
WARNING:root:The key is provided in the config. Assuming this is loaded from a pretrained module.
llama-2-chat loaded with interventions:
What's a cure for insomnia that always works?
There is no single cure for insomnia that works for everyone, and it's important to address the underlying causes of sleep problems. However, some strategies that may help improve sleep quality and duration include:
1. Practicing relaxation techniques, such as deep breathing, progressive mus
Path Patching with Trainable Interventions#
import pyvene as pv
def path_patching_with_DAS_config(
layer, last_layer, low_rank_dimension,
component="attention_output", unit="pos"
):
intervening_component = [{
"layer": layer, "component": component, "group_key": 0,
"intervention_type": pv.LowRankRotatedSpaceIntervention,
"low_rank_dimension": low_rank_dimension,
}]
restoring_components = []
if not component.startswith("mlp_"):
restoring_components += [{
"layer": layer, "component": "mlp_output", "group_key": 1,
"intervention_type": pv.VanillaIntervention,
}]
for i in range(layer+1, last_layer):
restoring_components += [{
"layer": i, "component": "attention_output", "group_key": 1,
"intervention_type": pv.VanillaIntervention},{
"layer": i, "component": "mlp_output", "group_key": 1,
"intervention_type": pv.VanillaIntervention
}]
intervenable_config = pv.IntervenableConfig(
intervening_component + restoring_components)
return intervenable_config, len(restoring_components)
_, tokenizer, gpt2 = pv.create_gpt2()
pv_config, num_restores = path_patching_with_DAS_config(4, 6, 1)
pv_gpt2 = pv.IntervenableModel(pv_config, model=gpt2)
loaded model
base = tokenizer("The capital of Spain is", return_tensors="pt")
restore_source = tokenizer("The capital of Spain is", return_tensors="pt")
source = tokenizer("The capital of Italy is", return_tensors="pt")
# zero-out grads
_ = pv_gpt2.model.eval()
for k, v in pv_gpt2.interventions.items():
v.zero_grad()
original_outputs, counterfactual_outputs = pv_gpt2(
base,
sources=[source, restore_source],
unit_locations={
"sources->base": 4
}
)
# put gradients on the trainable intervention only
counterfactual_outputs[0].sum().backward()
tensor(-0.0694, grad_fn=<SumBackward0>)
Intervene on ResNet with Lambda Functions#
Huggingface Vision model comes with the support of ResNet. Here, we show how we can use pyvene to intervene on a patch of pixels, like token in transformer, which is like a primitive object in ResNet or ConvNet based NNs.
Caveats: We go with a pretty much hard-coded way here, but you can customize the hook functions as you want. It does not have to be a lambda function as well.
import torch
import pyvene as pv
from datasets import load_dataset
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-18")
resnet = AutoModelForImageClassification.from_pretrained("microsoft/resnet-18")
dataset = load_dataset("huggingface/cats-image")
base_image = dataset["test"]["image"][0]
source_image = dataset["test"]["image"][0]
base_inputs = feature_extractor(base_image, return_tensors="pt")
source_inputs = feature_extractor(source_image, return_tensors="pt")
source_inputs['pixel_values'] += 0.5*torch.randn(source_inputs['pixel_values'].shape)
def create_mask():
_mask = torch.zeros((56, 56))
_mask[56//2:, 56//2:] = 1
return _mask
m = create_mask()
pv_resnet = pv.IntervenableModel({
"component": "resnet.embedder.pooler.output",
"intervention": lambda b, s: b * (1. - m) + s * m},
model=resnet
)
intervened_outputs = pv_resnet(
base_inputs, [source_inputs], return_dict=True, output_original_output=True
)
(intervened_outputs.intervened_outputs.logits - intervened_outputs.original_outputs.logits).sum()
tensor(0.0005)
Intervene on ResNet with Trainable Lambda Functions#
import torch
import pyvene as pv
from datasets import load_dataset
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-18")
resnet = AutoModelForImageClassification.from_pretrained("microsoft/resnet-18")
dataset = load_dataset("huggingface/cats-image")
base_image = dataset["test"]["image"][0]
source_image = dataset["test"]["image"][0]
base_inputs = feature_extractor(base_image, return_tensors="pt")
source_inputs = feature_extractor(source_image, return_tensors="pt")
source_inputs['pixel_values'] += 0.5*torch.randn(source_inputs['pixel_values'].shape)
# trainable DAS directions
v = torch.nn.utils.parametrizations.orthogonal(
torch.nn.Linear(56, 10))
pv_resnet = pv.IntervenableModel({
"component": "resnet.embedder.pooler.output",
"intervention": lambda b, s: b + ((s @ v.weight.T - b @ v.weight.T) @ v.weight)},
model=resnet
)
intervened_outputs = pv_resnet(
base_inputs, [source_inputs], return_dict=True, output_original_output=True
)
(intervened_outputs.intervened_outputs.logits - intervened_outputs.original_outputs.logits).sum()
tensor(0.0068, grad_fn=<SumBackward0>)
Run pyvene on NDIF backend with pv.build_intervenable_model(...)#
NDIF provides APIs for running intervened model inference calls either locally or remotely, enabling Pyvene to run intervened model calls remotely with shared resources. This is especially useful when the intervened model is large (e.g., Llama 400B).
Note that setting remote=True is still under-construction for remote intervention.
Basic activation collection
import torch
import pyvene as pv
from transformers import AutoTokenizer
from nnsight import LanguageModel
# load any huggingface model as a ndif native model object
gpt2_ndif = LanguageModel('openai-community/gpt2', device_map='cpu')
tokenizer = AutoTokenizer.from_pretrained('openai-community/gpt2')
# pyvene provides pv.build_intervenable_model as the generic model builder
pv_gpt2_ndif = pv.build_intervenable_model({
# based on the module printed above, you can access via string, input means the input to the module
"component": "transformer.h[10].attn.attn_dropout.input",
# you can also initialize the intervention gpt2_ndif
"intervention": pv.CollectIntervention()}, model=gpt2_ndif, remote=False)
base = "When John and Mary went to the shops, Mary gave the bag to"
ndif_collected_attn_w = pv_gpt2_ndif(
base = tokenizer(base, return_tensors="pt"
), unit_locations={"base": [h for h in range(12)]}
)[0][-1][0]
/u/nlp/anaconda/main/anaconda3/envs/wuzhengx-310/lib/python3.10/site-packages/transformers/utils/hub.py:124: FutureWarning: Using `TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
warnings.warn(
WARNING:root:We currently have very limited intervention support for ndif backend.
You're using a GPT2TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
# gpt2 helper loading model from HuggingFace
_, tokenizer, gpt2 = pv.create_gpt2()
pv_gpt2 = pv.IntervenableModel({
# based on the module printed above, you can access via string, input means the input to the module
"component": "h[10].attn.attn_dropout.input",
# you can also initialize the intervention outside
"intervention": pv.CollectIntervention()}, model=gpt2)
base = "When John and Mary went to the shops, Mary gave the bag to"
collected_attn_w = pv_gpt2(
base = tokenizer(base, return_tensors="pt"
), unit_locations={"base": [h for h in range(12)]}
)[0][-1][0]
torch.allclose(ndif_collected_attn_w, collected_attn_w)
loaded model
True
Interchange intervention (activation swap between two examples)
import pyvene as pv
from transformers import AutoTokenizer
from nnsight import LanguageModel
# load any huggingface model as a ndif native model object
gpt2_ndif = LanguageModel('openai-community/gpt2', device_map='cpu')
tokenizer = AutoTokenizer.from_pretrained('openai-community/gpt2')
# create with dict-based config
pv_config = pv.IntervenableConfig({
"component": "transformer.h[0].attn.output",
"intervention": pv.VanillaIntervention()}
)
#initialize model
pv_gpt2_ndif = pv.build_intervenable_model(
pv_config, model=gpt2_ndif)
# run an interchange intervention
intervened_outputs = pv_gpt2_ndif(
# the base input
base=tokenizer(
"The capital of Spain is",
return_tensors = "pt"),
# the source input
sources=tokenizer(
"The capital of Italy is",
return_tensors = "pt"),
# the location to intervene at (3rd token)
unit_locations={"sources->base": 3},
)
/u/nlp/anaconda/main/anaconda3/envs/wuzhengx-310/lib/python3.10/site-packages/transformers/utils/hub.py:124: FutureWarning: Using `TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
warnings.warn(
WARNING:root:We currently have very limited intervention support for ndif backend.
You're using a GPT2TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
Run LoRA with pyvene#
pyvene works just like any other PEFT library out there!
One key difference between LoRA interventions and ours is that our interventions do not consume the module’s inputs during the intervention.
For example, LoRA applies the update
h' = h + ABx, where x is the input to the module.
Our current interventions apply
h' = h + vector, which modifies only the module’s output.
If you want the intervention to use the inputs, simply enable the as_adaptor flag during initialization!
import torch
import pyvene as pv
_, tokenizer, gpt2 = pv.create_gpt2()
class GhostLoRAIntervention(
pv.ConstantSourceIntervention):
def __init__(self, **kwargs):
super().__init__(keep_last_dim=True)
self.W_A = torch.rand(768, 1)
self.W_B = torch.rand(1, 768)
def forward(
self, base, source=None, subspaces=None, **kwargs):
x = kwargs["args"][0]
print(x.shape)
print(base.shape)
return base + x@self.W_A@self.W_B
# run with new intervention type
pv_gpt2 = pv.IntervenableModel({
"component": "h[10].attn.c_proj.output",
"intervention": GhostLoRAIntervention()}, model=gpt2,
as_adaptor=True)
intervened_outputs = pv_gpt2(
base = tokenizer("The capital of Spain is",
return_tensors="pt"), unit_locations=None) # LoRA applies to all positions.
WARNING:root:as_adaptor is turned on. This means the intervention will take the input arguments of the intervening module as well.
loaded model
torch.Size([1, 5, 768])
torch.Size([1, 5, 768])
The End#
Now you are graduating from pyvene entry level course! Feel free to take a look at our tutorials for more challenging interventions.