
Download CoreNLP 4.5.10 CoreNLP on GitHub CoreNLP on 🤗
What’s new: The v4.5.3 release adds an Ssurgeon interface. 4.5.10 removes the patterns package to remove the Lucene dependency, as the latest Java 8 version of Lucene has an unpatched security issue. If you want the patterns package restored for a later Java 11 release, please file an issue on github
About
CoreNLP is your one stop shop for natural language processing in Java! CoreNLP enables users to derive linguistic annotations for text, including token and sentence boundaries, parts of speech, named entities, numeric and time values, dependency and constituency parses, coreference, sentiment, quote attributions, and relations. CoreNLP currently supports 8 languages: Arabic, Chinese, English, French, German, Hungarian, Italian, and Spanish.
Pipeline
The centerpiece of CoreNLP is the pipeline. Pipelines take in raw text, run a series of NLP annotators on the text, and produce a final set of annotations.
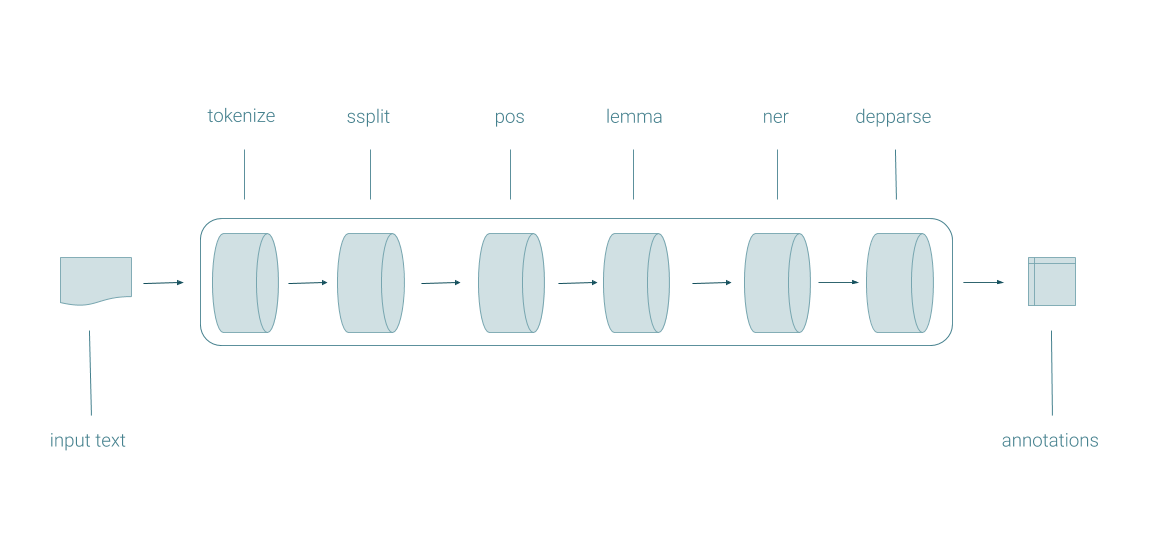
CoreDocument
Pipelines produce CoreDocuments, data objects that contain all of the annotation information, accessible with a simple API, and serializable to a Google Protocol Buffer.
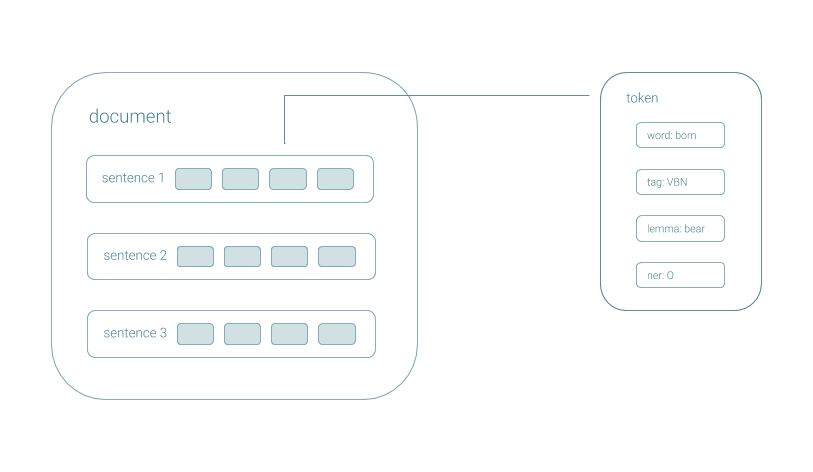
Annotations
CoreNLP generates a variety of linguistic annotations, including:
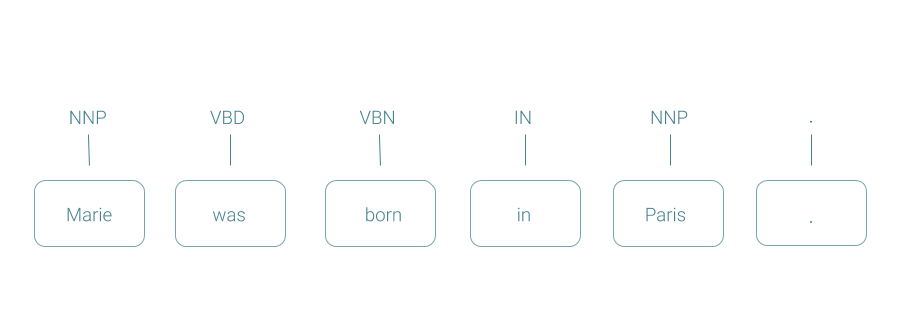
Parts Of Speech
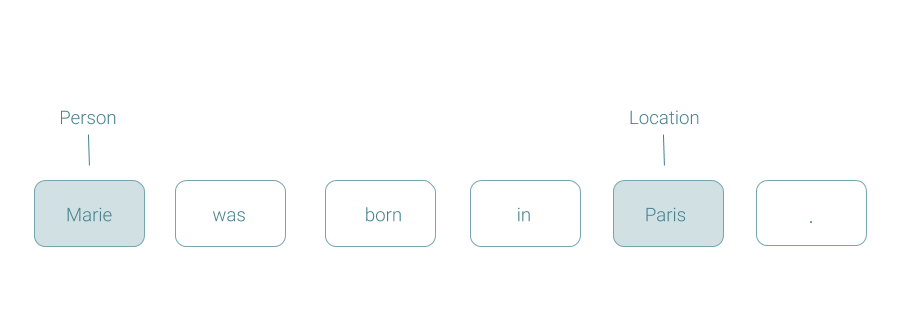
Named Entities
Dependency Parses
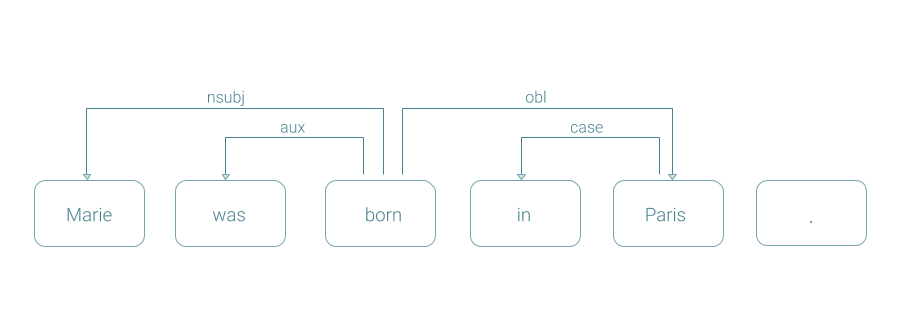
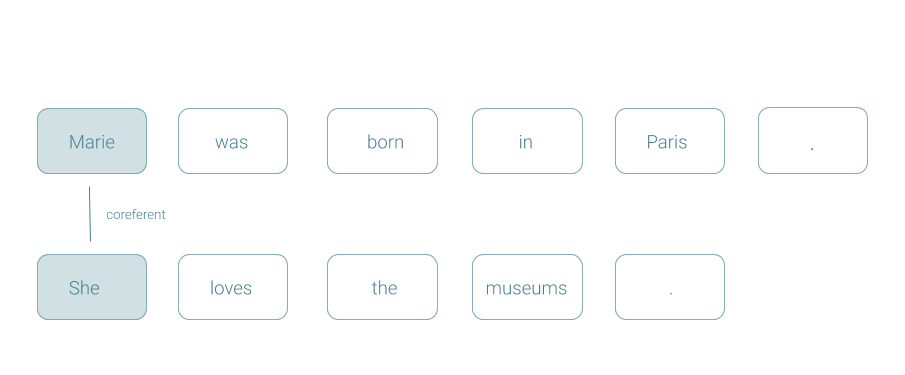
Coreference
Quickstart
Download and unzip CoreNLP 4.5.10 (HF Hub)
Download model jars for the language you want to work on and move the jars to the distribution directory. Jars are available directly from us, from Maven, and from Hugging Face.
| Language | Model Jar | Version |
|---|---|---|
| Arabic | download (mirror) (HF Hub) | 4.5.10 |
| Chinese | download (mirror) (HF Hub) | 4.5.10 |
| English (extra) | download (mirror) (HF Hub) | 4.5.10 |
| English (KBP) | download (mirror) (HF Hub) | 4.5.10 |
| French | download (mirror) (HF Hub) | 4.5.10 |
| German | download (mirror) (HF Hub) | 4.5.10 |
| Hungarian | download (mirror) (HF Hub) | 4.5.10 |
| Italian | download (mirror) (HF Hub) | 4.5.10 |
| Spanish | download (mirror) (HF Hub) | 4.5.10 |
Thank you to HuggingFace for helping with our hosting!
mv /path/to/stanford-corenlp-4.5.10-models-french.jar /path/to/stanford-corenlp-4.5.10
- Include the distribution directory in your CLASSPATH.
export CLASSPATH=$CLASSPATH:/path/to/stanford-corenlp-4.5.10/*:
- You’re ready to go! There are many ways to run a CoreNLP pipeline. For instance here’s how to run a pipeline on a text file. The output will be available in a file called
input.txt.out.
java edu.stanford.nlp.pipeline.StanfordCoreNLP -file input.txt
Programming languages and operating systems
Stanford CoreNLP is written in Java; recent releases require Java 8+. You need to have Java installed to run CoreNLP. However, you can interact with CoreNLP via the command-line or its web service; many people use CoreNLP while writing their own code in Javascript, Python, or some other language.
You can use Stanford CoreNLP from the command-line, via its original Java programmatic API, via the object-oriented simple API, via third party APIs for most major modern programming languages, or via a web service. It works on Linux, macOS, and Windows.
License
The full Stanford CoreNLP is licensed under the GNU General Public License v3 or later. More precisely, all the Stanford NLP code is GPL v2+, but CoreNLP uses some Apache-licensed libraries, and so our understanding is that the the composite is correctly licensed as v3+. You can run almost all of CoreNLP under GPL v2; you simply need to omit the time-related libraries, and then you lose the functionality of SUTime. Note that the license is the full GPL, which allows many free uses, but not its use in proprietary software which is distributed to others. For distributors of proprietary software, CoreNLP is also available from Stanford under a commercial licensing You can contact us at java-nlp-support@lists.stanford.edu. If you don’t need a commercial license, but would like to support maintenance of these tools, we welcome gift funding: use this form and write “Stanford NLP Group open source software” in the Special Instructions.
Citing Stanford CoreNLP in papers
If you’re just running the CoreNLP pipeline, please cite this CoreNLP paper:
Manning, Christopher D., Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP Natural Language Processing Toolkit In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 55-60. [pdf] [bib]
If you’re dealing in depth with particular annotators, you’re also encouraged to cite the papers that cover individual components: POS tagging, NER, constituency parsing, dependency parsing, coreference resolution, sentiment, or Open IE. You can find more information on the Stanford NLP software pages and/or publications page.