Pipeline
Table of contents
Pipeline
The centerpiece of CoreNLP is the pipeline. Pipelines take in text or xml and generate full annotation objects.
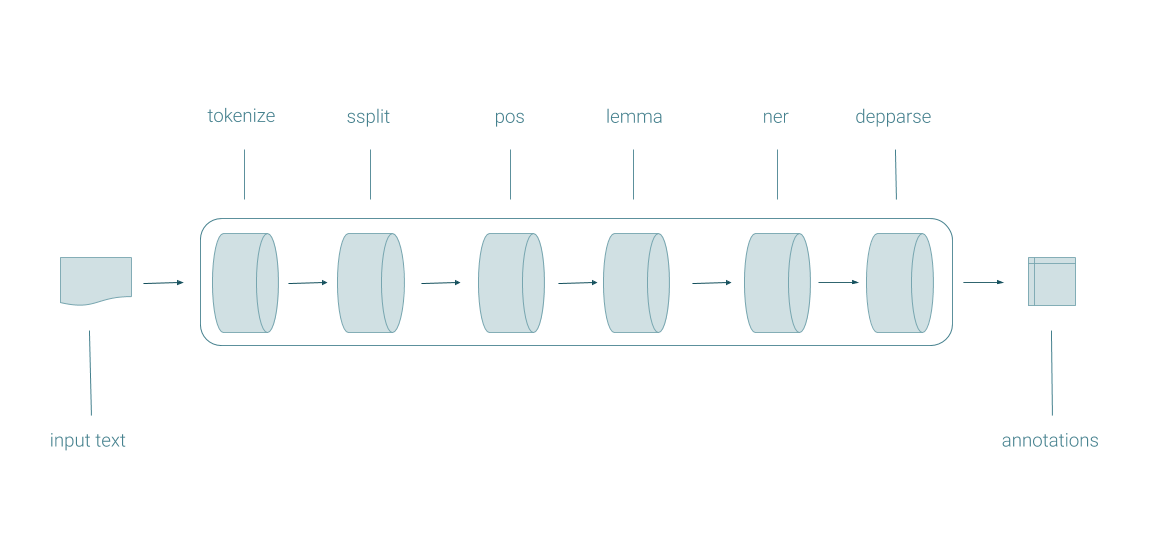
Pipelines are constructed with Properties objects which provide specifications for what annotators to run and how to customize the annotators.
Running A Pipeline From The Command Line
You can immediately run a pipeline by issuing the following command:
java edu.stanford.nlp.pipeline.StanfordCoreNLP -file input.txt
The output will be stored in the file input.txt.out, and will by default contain a human readable presentation of the annotations.
You can customize your pipeline by providing properties in a properties file.
Here is an example properties file stored at example.props:
# output JSON instead
outputFormat = json
# list of annotators to run
annotators = tokenize,pos
# customize the pos model
pos.model = edu/stanford/nlp/models/pos-tagger/english-bidirectional-distsim.tagger
Here is the command for running a pipeline with these configurations:
java edu.stanford.nlp.pipeline.StanfordCoreNLP -props example.props -file input.txt
This will store JSON output in the file input.txt.json.
Of course all of those properties could be specified at the command line as well:
java edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,pos -pos.model edu/stanford/nlp/models/pos-tagger/english-bidirectional-distsim.tagger -outputFormat json -file input.txt
If you want to run a non-English language pipeline, you can just specify the name of one of the CoreNLP supported languages:
java edu.stanford.nlp.pipeline.StanfordCoreNLP -props french -file french-input.txt
Running A Pipeline In Java Code
Here is a basic demo class showing how to run a pipeline in Java code:
package edu.stanford.nlp.examples;
import edu.stanford.nlp.io.*;
import edu.stanford.nlp.pipeline.*;
import java.util.*;
public class PipelineExample {
public static String text = "Marie was born in Paris.";
public static void main(String[] args) {
// set up pipeline properties
Properties props = new Properties();
// set the list of annotators to run
props.setProperty("annotators", "tokenize,pos,lemma,ner,depparse");
// build pipeline
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// create a document object
CoreDocument document = pipeline.processToCoreDocument(text);
}
}
To customize pipelines in Java, add properties to the Properties object in the same way the annotators property is set in the code example.
Table of contents
- Full List Of Annotators
- Custom Annotators
- Tokenization
- CleanXML
- Sentence Splitting
- Multi Word Token Expansion
- Parts Of Speech
- Lemmatization
- Named Entity Recognition
- Dependency Parsing
- Constituency Parsing
- Coreference Resolution
- OpenIE
- KBP
- Entity Linking
- Quote Extraction And Attribution
- Sentiment