Dependency Parser
Table of contents
Introduction
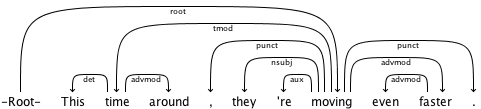
A dependency parser analyzes the grammatical structure of a sentence, establishing relationships between “head” words and words which modify those heads. The figure below shows a dependency parse of a short sentence. The arrow from the word moving to the word faster indicates that faster modifies moving , and the label advmod assigned to the arrow describes the exact nature of the dependency.
We have built a super-fast transition-based parser which produces typed dependency parses of natural language sentences. The parser is powered by a neural network which accepts word embedding inputs, as described in the paper:
Danqi Chen and Christopher Manning. 2014. A Fast and Accurate Dependency Parser Using Neural Networks. In Proceedings of EMNLP 2014.
This parser supports English (with Universal Dependencies, Stanford Dependencies and CoNLL Dependencies) and Chinese (with CoNLL Dependencies). Future versions of the software will support other languages.
How transition-based parsing works
For a quick introduction to the standard approach to transition-based dependency parsing, see Joakim Nivre’s EACL 2014 tutorial.
This parser builds a parse by performing a linear-time scan over the words of a sentence. At every step it maintains a partial parse, a stack of words which are currently being processed, and a buffer of words yet to be processed.
The parser continues to apply transitions to its state until its buffer is empty and the dependency graph is completed.
The initial state is to have all of the words in order on the buffer, with a single dummy ROOT node on the stack. The following transitions can be applied:
- LEFT-ARC: marks the second item on the stack as a dependent of the first item, and removes the second item from the stack (if the stack contains at least two items).
- RIGHT-ARC: marks the first item on the stack as a dependent of the second item, and removes the first item from the stack (if the stack contains at least two items).
- SHIFT: removes a word from the buffer and pushes it onto the stack (if the buffer is not empty).
With just these three types of transitions, a parser can generate any projective dependency parse. Note that for a typed dependency parser, with each transition we must also specify the type of the relationship between the head and dependent being described.
The parser decides among transitions at each state using a neural network classifier. Distributed representations (dense, continuous vector representations) of the parser’s current state are provided as inputs to this classifier, which then chooses among the possible transitions to make next. These representations describe various features of the current stack and buffer contents in the parser state.
The classifier which powers the parser is trained using an oracle. This oracle takes each sentence in the training data and produces many training examples indicating which transition should be taken at each state to reach the correct final parse. The neural network is trained on these examples using adaptive gradient descent (AdaGrad) with hidden unit dropout.
Obtaining the software
You may download either of the following packages:
- The Stanford Parser and the Stanford POS Tagger; or
- all of Stanford CoreNLP, which contains the parser, the tagger, and other things which you may or may not need.
Models
Trained models for use with this parser are included in either of the packages. The list of models currently distributed is:
- edu/stanford/nlp/models/parser/nndep/english_UD.gz ( default, English, Universal Dependencies)
- edu/stanford/nlp/models/parser/nndep/english_SD.gz (English, Stanford Dependencies)
- edu/stanford/nlp/models/parser/nndep/PTB_CoNLL_params.txt.gz (English, CoNLL Dependencies)
- edu/stanford/nlp/models/parser/nndep/CTB_CoNLL_params.txt.gz (Chinese, CoNLL Dependencies)
(TODO: this list is probably out of date)
Note that these models were trained with an earlier Matlab version of the code, and your results training with the Java code may be slightly worse.
Usage
Command-line interface
The dependency parser can be run as part of the larger CoreNLP pipeline, or run directly (external to the pipeline).
Using the Stanford CoreNLP pipeline
This parser is integrated into Stanford CoreNLP as a new annotator.
If you want to use the transition-based parser from the command line, invoke StanfordCoreNLP with the depparse annotator. This annotator has dependencies on the tokenize and pos annotators. An example invocation follows (assuming CoreNLP is on your classpath):
java edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,pos,depparse -file <INPUT_FILE>
Direct access (with Stanford Parser or CoreNLP)
It is also possible to access the parser directly in the Stanford Parser or Stanford CoreNLP packages. With direct access to the parser, you can train new models, evaluate models with test treebanks, or parse raw sentences. Note that this package currently still reads and writes CoNLL-X files, not CoNLL-U files.
The main program to use is the class edu.stanford.nlp.parser.nndep.DependencyParser. The Javadoc for this class’ main method describes all possible options in details. Some usage examples follow:
- Parse raw text from a file:
java edu.stanford.nlp.parser.nndep.DependencyParser -model modelOutputFile.txt.gz -textFile rawTextToParse -outFile dependenciesOutputFile.txt
- Parse raw text from standard input, writing to standard output:
java edu.stanford.nlp.parser.nndep.DependencyParser -model modelOutputFile.txt.gz -textFile - -outFile -
- Parse a CoNLL-X file, writing the output as a CoNLL-X file:
java edu.stanford.nlp.parser.nndep.DependencyParser -model edu/stanford/nlp/models/parser/nndep/english_UD.gz -testFile test.conllx -outFile test-output.conllx
The options for specifying files to the parser at training and test time are:
| Option | Required for training | Required for testing / parsing | Description |
|---|---|---|---|
‑devFile | Optional | No | Path to a development-set treebank in CoNLL-X format. If provided, the dev set performance is monitored during training. |
‑embedFile | Optional (recommended!) | No | A word embedding file, containing distributed representations of English words. Each line of the provided file should contain a single word followed by the elements of the corresponding word embedding (space-delimited). It is not absolutely necessary that all words in the treebank be covered by this embedding file, though the parser’s performance will generally improve if you are able to provide better embeddings for more words. |
‑model | Yes | Yes | Path to a model file. If the path ends in .gz, the model will be read as a Gzipped model file. During training, we write to this path; at test time we read a pre-trained model from this path. |
‑textFile | No | Yes (or testFile) | Path to a plaintext file containing sentences to be parsed. |
‑testFile | No | Yes (or textFile) | Path to a test-set treebank in CoNLL-X format for final evaluation of the parser. |
‑trainFile | Yes | No | Path to a training treebank in CoNLL-X format. |
Programmatic access
Included demo
It’s also possible to use this parser directly in your own Java code. There is an DependencyParserDemo example class in the package edu.stanford.nlp.parser.nndep.demo, included in the source of the Stanford Parser and the source of CoreNLP.
Java API
The parser exposes an API for both training and testing. You can find more information in our Javadoc.
Training your own parser
You can train a new dependency parser using your own data in the CoNLL-X data format. (Many dependency treebanks are provided in this format by default; even if not, conversion is often trivial.)
Python Version
There is now a Python package which uses torch to simplify parser training. It should also be faster, given the GPU capabilities.
https://github.com/stanfordnlp/nn-depparser
Basic guidelines
To train a new English model, you need the following pieces of data:
- A dependency treebank , split into training, development, and test segments. (Most treebanks come with a predetermined split.)
- A word embedding file, containing distributed representations of English words. It is not absolutely necessary that all words in the treebank be covered by this embedding file, though the parser’s performance will generally improve if you are able to provide better embeddings for more words.
This word embedding file is only used for training. The parser will build its own improved embeddings and save them as part of the learned model.
To start training with the data described above, run this command with the parser on your classpath:
`java edu.stanford.nlp.parser.nndep.DependencyParser -trainFile
-devFile -embedFile -embeddingSize -model nndep.model.txt.gz`
On the Stanford NLP machines, training data is available in /u/nlp/data/depparser/nn/data:
java edu.stanford.nlp.parser.nndep.DependencyParser -trainFile /u/nlp/data/depparser/nn/data/dependency_treebanks/PTB_Stanford/train.conll -devFile /u/nlp/data/depparser/nn/data/dependency_treebanks/PTB_Stanford/dev.conll -embedFile /u/nlp/data/depparser/nn/data/embeddings/en-cw.txt -embeddingSize 50 -model nndep.model.txt.gz
Training models for other languages
To train the parser for languages other than English, you need the data as described in the previous section, along with a TreebankLanguagePack describing the particularities of your treebank and the language it contains. (The Stanford Parser package may already contain a TLP for your language of choice: check the package edu.stanford.nlp.trees.international.)
Note that at test time, a language appropriate tagger will also be necessary.
For example, here is a command used to train a Chinese model. The only difference from the English case (apart from the fact that we changed datasets) is that we also provide a different TreebankLanguagePack class with the -tlp option.
java edu.stanford.nlp.parser.nndep.DependencyParser **-tlp edu.stanford.nlp.trees.international.pennchinese.ChineseTreebankLanguagePack** -trainFile chinese/train.conll -devFile chinese/dev.conll -embedFile chinese/embeddings.txt -embeddingSize 50 -model nndep.chinese.model.txt.gz
The only complicated part here is the TreebankLanguagePack, which is a Java class you need to provide. It’s not hard to write. It’s only used for a couple of things: A default character encoding, a list of punctuation POS tags and sentence final punctuation words, and to specify a tokenizer (which you might also need to write). Some of these, like the tokenizer, are only needed for running the parser on raw text, and you can train and test on CoNLL files without one. Getting started, if your language uses the Latin alphabet, you can probably get away with using the default English TreebankLanguagePack, PennTreebankLanguagePack.
Additional training options
| Option | Default | Description |
|---|---|---|
-adaAlpha | 0.01 | Global learning rate for AdaGrad training. |
-adaEps | 1e-6 | Epsilon value added to the denominator of AdaGrad update expression for numerical stability. |
-batchSize | 10000 | Size of mini-batch used for training. |
-dropProb | 0.5 | Dropout probability. For each training example we randomly choose some amount of units to disable in the neural network classifier. This parameter controls the proportion of units “dropped out.” |
-embeddingSize | 50 | Dimensionality of word embeddings provided. |
-evalPerIter | 100 | Run full UAS (unlabeled attachment score) evaluation on the development set every time we finish this number of iterations. |
-hiddenSize | 200 | Dimensionality of hidden layer in neural network classifier. |
-initRange | 0.01 | Bounds of range within which weight matrix elements should be initialized. Each element is drawn from a uniform distribution over the range [-initRange, initRange]. |
-maxIter | 20000 | Number of training iterations to complete before stopping and saving the final model. |
-numPreComputed | 100000 | The parser pre-computes hidden-layer unit activations for particular inputs words at both training and testing time in order to speed up feedforward computation in the neural network. This parameter determines how many words for which we should compute hidden-layer activations. |
-regParameter | 1e-8 | Regularization parameter for training. |
-trainingThreads | 1 | Number of threads to use during training. Note that depending on training batch size, it may be unwise to simply choose the maximum amount of threads for your machine. On our 16-core test machines: a batch size of 10,000 runs fastest with around 6 threads; a batch size of 100,000 runs best with around 10 threads. |
-wordCutOff | 1 | The parser can optionally ignore rare words by simply choosing an arbitrary “unknown” feature representation for words that appear with frequency less than n in the corpus. This n is controlled by the wordCutOff parameter. |
Runtime parsing options
| Option | Default | Description |
|---|---|---|
-escaper | N/A | Only applicable for testing with -textFile. If provided, use this word-escaper when parsing raw sentences. Should be a fully-qualified class name like edu.stanford.nlp.trees.international.arabic.ATBEscaper. |
-numPreComputed | 100000 | The parser pre-computes hidden-layer unit activations for particular inputs words at both training and testing time in order to speed up feedforward computation in the neural network. This parameter determines how many words for which we should compute hidden-layer activations. |
-sentenceDelimiter | N/A | Only applicable for testing with -textFile. If provided, assume that the given textFile has already been sentence-split, and that sentences are separated by this delimiter. |
-tagger.model | edu/stanford/nlp/models/pos-tagger/english-left3words/english-left3words-distsim.tagger | Only applicable for testing with -textFile. Path to a part-of-speech tagger to use to pre-tag the raw sentences before parsing. |
Performance
The table below describes this parser’s performance on the Penn Treebank, converted to dependencies using Stanford Dependencies. The part-of-speech tags used as input for training and testing were generated by the Stanford POS Tagger (using the bidirectional5words model).
| Data | Metric | Score |
|---|---|---|
| Development (1700 sentences) | UAS | 92.0 |
| LAS | 89.7 | |
| Test (2416 sentences) | UAS | 91.7 |
| LAS | 89.5 |