Stanza – A Python NLP Package for Many Human Languages



Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text, Stanza divides it into sentences and words, and then can recognize parts of speech and entities, do syntactic analysis, and more. Stanza brings state-of-the-art NLP models to languages of your choosing.
Table of contents
About
Stanza is a Python natural language analysis package. It contains tools, which can be used in a pipeline, to convert a string containing human language text into lists of sentences and words, to generate base forms of those words, their parts of speech and morphological features, to give a syntactic structure dependency parse, and to recognize named entities. The toolkit is designed to be parallel among more than 70 languages, using the Universal Dependencies formalism.
Stanza is built with highly accurate neural network components that also enable efficient training and evaluation with your own annotated data. The modules are built on top of the PyTorch library. You will get much faster performance if you run the software on a GPU-enabled machine.
In addition, Stanza includes a Python interface to the CoreNLP Java package and inherits additional functionality from there, such as constituency parsing, coreference resolution, and linguistic pattern matching. (However, you do not need to have CoreNLP to use any of the core, native Stanza functionality.)
To summarize, Stanza features:
- Native Python implementation requiring minimal efforts to set up;
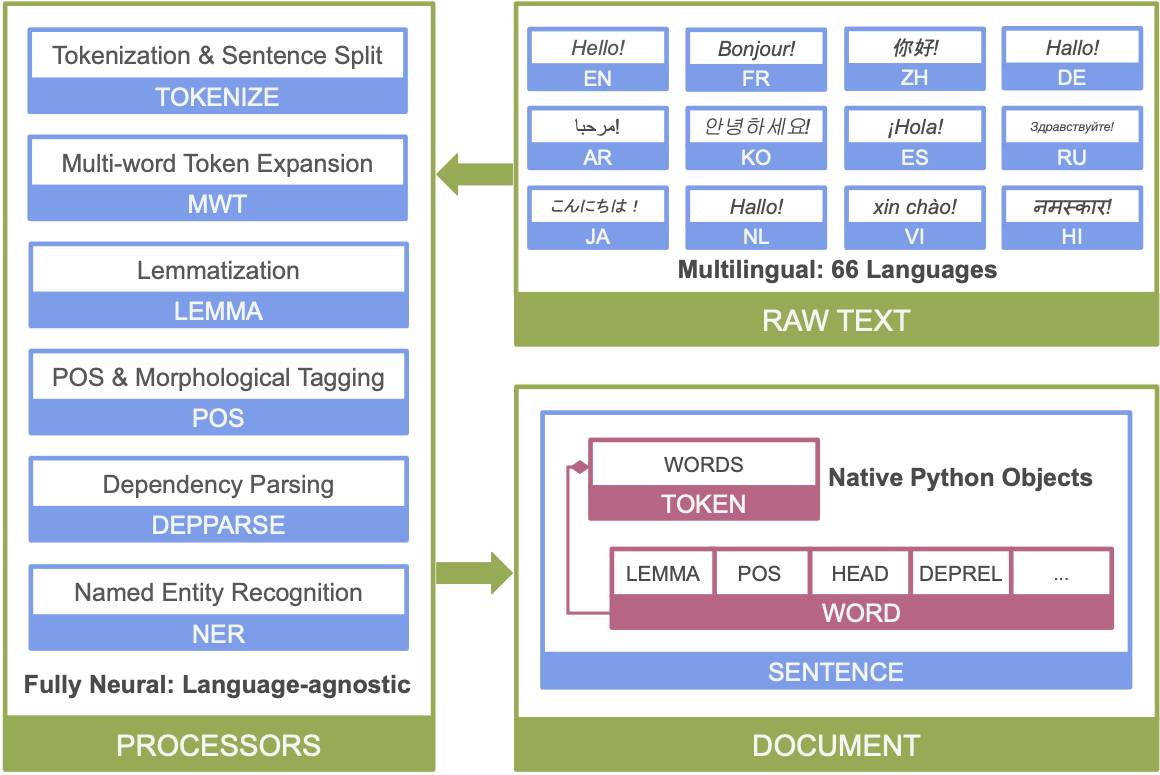
- Full neural network pipeline for robust text analytics, including tokenization, multi-word token (MWT) expansion, lemmatization, part-of-speech (POS) and morphological features tagging, dependency parsing, and named entity recognition;
- Pretrained neural models supporting 70 (human) languages;
- A stable, officially maintained Python interface to CoreNLP.
Below is an overview of Stanza’s neural network NLP pipeline:
Getting Started
We strongly recommend installing Stanza with pip, which is as simple as:
pip install stanza
To see Stanza’s neural pipeline in action, you can launch the Python interactive interpreter, and try the following commands:
>>> import stanza
>>> stanza.download('en') # download English model
>>> nlp = stanza.Pipeline('en') # initialize English neural pipeline
>>> doc = nlp("Barack Obama was born in Hawaii.") # run annotation over a sentence
You should be able to see all the annotations in the example by running the following commands:
>>> print(doc)
>>> print(doc.entities)
For more details on how to use the neural network pipeline, please see our Installation, Getting Started Guide, and Tutorials pages.
Aside from the neural pipeline, Stanza also provides the official Python wrapper for accessing the Java Stanford CoreNLP package. For more details, please see Stanford CoreNLP Client.
If you run into issues or bugs during installation or when you run Stanza, please check out the FAQ page. If you cannot find your issue there, please report it to us via GitHub Issues. A GitHub issue is also appropriate for asking general questions about using Stanza - please search the closed issues first!
License
Stanza is licensed under the Apache License, Version 2.0 (the “License”); you may not use the software package except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Main Contributors
The PyTorch implementation of Stanza’s neural pipeline is due to Peng Qi, Yuhao Zhang, and Yuhui Zhang, with help from Jason Bolton, Tim Dozat and John Bauer. John Bauer currently leads the maintenance of this package.
The CoreNLP client was mostly written by Arun Chaganty, and Jason Bolton spearheaded merging the two projects together.
We are also grateful to community contributors for their help in improving Stanza.
Citing Stanza in papers
If you use Stanza in your work, please cite this paper:
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton and Christopher D. Manning. 2020. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. In Association for Computational Linguistics (ACL) System Demonstrations. 2020. [pdf][bib]
If you use the biomedical and clinical model packages in Stanza, please also cite our JAMIA biomedical models paper:
Yuhao Zhang, Yuhui Zhang, Peng Qi, Christopher D. Manning, Curtis P. Langlotz. Biomedical and Clinical English Model Packages in the Stanza Python NLP Library, Journal of the American Medical Informatics Association. 2021.
If you use Stanford CoreNLP through the Stanza python client, please also follow the instructions here to cite the proper publications.
Links
GitHub Online Demo PyPI CoreNLP Stanford NLP Group